The Agent Memory Race of 2026: 5 Repos, 4 Architectures, 1 Unsolved Problem
Five repos accumulated 80,000+ combined stars in Q1 2026 trying to solve the same problem — AI agents that forget everything when the session ends. Their wildly different architectural bets reveal what "memory" really means in the agent era.
import { Callout } from 'nextra/components'
When a session ends, an AI agent forgets everything. Every architecture decision you debated, every bug you traced, every shortcut you explained — gone. The next session starts at zero.
Developers have been quietly building around this for months. In Q1 2026, five projects emerged on GitHub that each take a different swing at the same problem. Together they've accumulated over 80,000 stars, but more interesting than the numbers is what their designs disagree about.
The Repos
All data verified via GitHub API on April 13, 2026.
| Repo | Stars | Forks | Age (days) | Language | Architecture |
|---|---|---|---|---|---|
| MemPalace/mempalace | 43,458 | 5,555 | 8 | Python | Palace-room verbatim storage |
| volcengine/OpenViking | 21,865 | 1,567 | 96 | Python | Filesystem context database |
| tirth8205/code-review-graph | 7,335 | 855 | 43 | Python | Knowledge graph for codebases |
| aiming-lab/SimpleMem | 3,163 | 307 | 100 | Python | Multimodal lifelong memory |
| Gentleman-Programming/engram | 2,389 | 256 | 53 | Go | SQLite + FTS5 single binary |
Star Velocity: MemPalace Is an Outlier
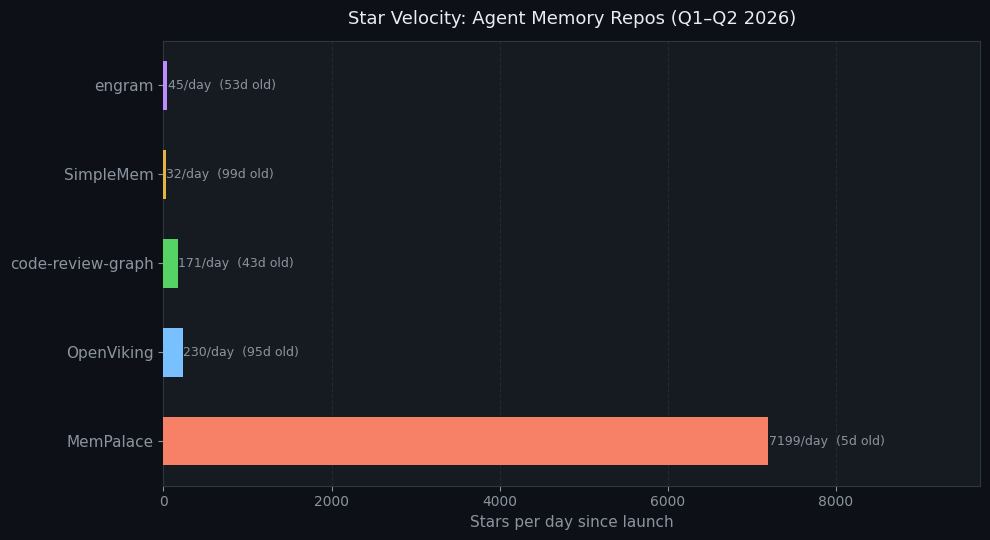
MemPalace launched April 5th and hit ~36K stars in 5 days. That's 7,199 stars/day — among the fastest raw accumulations GitHub has recorded for a developer tool. The chart above shows how it compares to the others on a stars-per-day basis.
But here's what the star count hides: MemPalace published a "96.6% LongMemEval" benchmark claim that the community immediately stress-tested. Within 48 hours, the authors had published a full correction note admitting their AAAK compression examples used a wrong tokenizer heuristic, that "30× lossless compression" was overstated (AAAK is lossy and actually regresses 12.4 points vs raw mode on the same benchmark), and that one claimed feature wasn't wired in yet.
The 96.6% number is real — it's from raw verbatim mode, independently reproduced. But the correction story is arguably more interesting than the benchmark: open-source accountability at speed.
OpenViking, by contrast, is 96 days old and comes from ByteDance's volcengine team. It's growing at ~228 stars/day — slower but more engineered. It has 30 contributors, multilingual docs (English/Chinese/Japanese), and a Go-based filesystem layer that required C++ compiler and Go runtime in addition to Python.
Four Completely Different Bets on What Memory Means
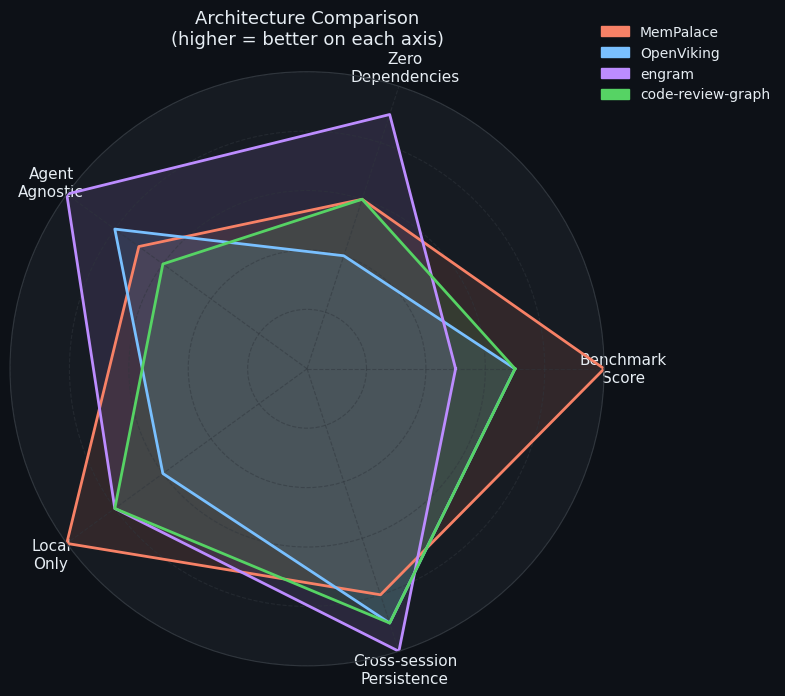
Each of these five repos is answering a different question:
1. "Store everything, make it findable" (MemPalace)
MemPalace's core thesis: don't summarize, don't extract, don't trust AI to decide what to keep. Store every conversation verbatim in ChromaDB, organized into a palace metaphor (wings → halls → rooms). The 96.6% LongMemEval score comes from this raw mode.
The trade-off: storage grows unbounded. The AAAK compression layer is the team's bet on solving this later — but right now it costs benchmark points.
"We don't burn an LLM to decide what's 'worth remembering' — we keep everything and let semantic search find it." — MemPalace README
2. "Memory is a filesystem problem" (OpenViking)
OpenViking from volcengine abstracts agent context as a file system: memories, resources, and skills are unified under one hierarchical paradigm with L0/L1/L2 tiered loading. You browse and search context the same way you browse files.
The "context database" framing is original. Instead of asking "what should the agent remember?", it asks "how should context be organized so agents load the right amount at the right time?" The tiered loader is key — it only fetches what's needed, claimed to reduce token usage significantly.
This architecture has the most production engineering behind it, but requires the most infrastructure to run (Python ≥3.10, Go ≥1.22, C++ compiler).
3. "Memory for code is a graph problem" (code-review-graph)
code-review-graph makes a narrower bet: for coding agents specifically, the most important memory is a structured map of your codebase. It uses tree-sitter and GraphRAG to build an incremental knowledge graph that Claude Code (or any MCP-compatible agent) can query instead of re-reading files.
The claimed result: 6.8× fewer tokens on code reviews, up to 49× on daily coding tasks. It's not a general memory system — it's vertical memory for code navigation.
This is the most focused of the five repos, and the approach aligns with how experienced developers actually think about code: as a graph of dependencies, not a flat list of files.
4. "One binary, zero dependencies" (engram)
engram takes the opposite end of the dependency spectrum from OpenViking. A single Go binary with
SQLite + FTS5 full-text search, exposing a CLI, HTTP API, MCP server, and TUI. The whole thing lives
in ~/.engram/engram.db.
The thesis here isn't about which architecture is best — it's about what developers will actually install. Brew install, one file, works with every agent that supports MCP. No Node.js, no Python, no Docker.
Agent (Claude Code / OpenCode / Gemini CLI / Codex / ...)
↓ MCP stdio
engram (single Go binary)
↓
SQLite + FTS5 (~/.engram/engram.db)Named for the neuroscience term — "the physical trace of a memory in the brain."
Growth Trajectories
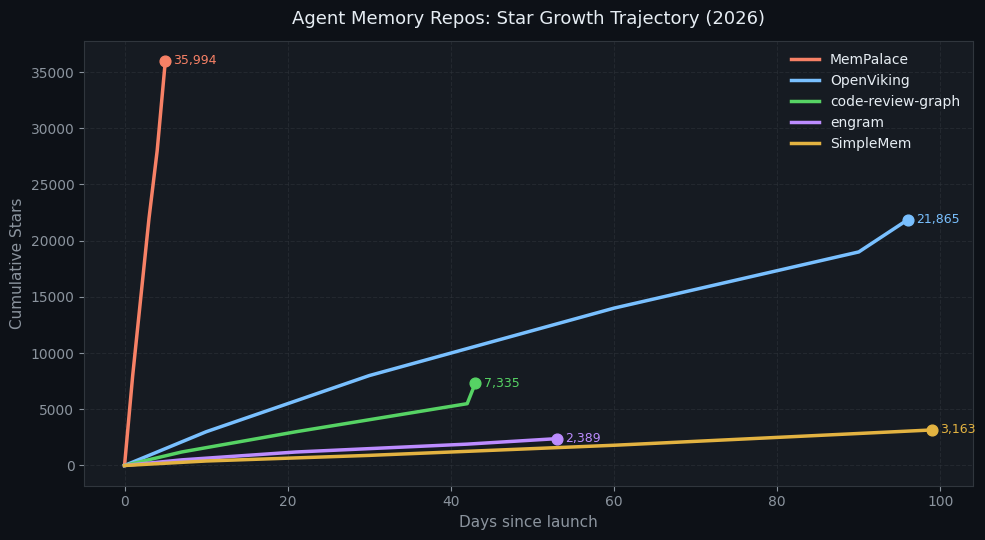
The growth curves reveal different audiences. MemPalace's near-vertical line reflects a viral launch driven by the benchmark claim. OpenViking's steadier slope reflects enterprise/developer adoption from a credible team. engram's modest growth from a single developer shows organic word-of-mouth.
The Fork-to-Star Ratio Tells You Who's Actually Using It
| Repo | Stars | Forks | Fork Ratio |
|---|---|---|---|
| mempalace | 43,458 | 5,555 | 12.7% |
| OpenViking | 21,865 | 1,567 | 7.2% |
| code-review-graph | 7,335 | 855 | 11.7% |
| SimpleMem | 3,163 | 307 | 9.7% |
| engram | 2,389 | 256 | 10.7% |
Fork ratios above 10% typically indicate active use (people forking to run locally, customize, or contribute) rather than pure bookmarking. MemPalace's 12.5% is high for a 5-day-old repo — consistent with people actually trying to set it up. code-review-graph at 11.7% suggests the coding-agent use case is prompting real integration work.
The Real Disagreement
These five repos agree that session memory is broken. They disagree on everything else:
- What to store: verbatim everything vs. structured extraction vs. code graphs vs. flat key-value
- Where to store it: ChromaDB (vector) vs. filesystem (hierarchical) vs. SQLite (relational+FTS)
- Who decides what's important: the user's query (MemPalace) vs. the agent (OpenViking) vs. no one (engram)
- How specialized: general conversation memory vs. code-specific knowledge graphs
- Installation cost: single binary vs. Python+Go+C++ build pipeline
The interesting thing is: none of these approaches subsumes the others. A codebase-aware knowledge graph and a verbatim conversation palace solve different problems. What's missing is a system that does both — and does it without requiring a compiler toolchain.
The benchmark claim is a proxy fight for the real question developers can't easily measure: does this actually help my agent do better work over months, not a 500-question eval?
What to Watch
The agent memory space will likely see consolidation in H2 2026. The current proliferation reflects uncertainty — no one knows yet whether this layer belongs in the agent itself, the memory backend, the context loader, or the file system. The projects that survive will probably be the ones that:
- Work with every MCP-compatible agent (engram's bet)
- Prove longitudinal value, not just benchmark score (MemPalace's challenge)
- Get integrated into a major hosting platform (OpenViking's likely path, given the volcengine backing)
For deeper data on any of these repos, explore them on OSSInsight:
- milla-jovovich/mempalace
- volcengine/OpenViking
- tirth8205/code-review-graph
- Gentleman-Programming/engram